

By Enric Gibert
On May 30th 2022, the Top500 High-Performance Computing (HPC) list revealed the first exa-scale HPC system ever constructed: the Frontier system at Oak Ridge National Laboratory (ORNL) in Tennessee, United States.
Why is TOP500?
The TOP500 is a non-profit group of experts and Key-Opinion leaders that compiles and processes information on HPC systems and makes all this information available to the HPC community. The group is formed by Erich Strohmaier, Jack Dongarra (I remember reading his papers when I was an undergrad in the 90s), Horst Simon and Martin Meuer.
Among other useful information, twice a year the group compiles the list of the 500 most powerful HPC systems based on their achieved performance (achieved versus peak performance is discussed later in this article). Information compilation is a collaborative effort between these experts and the different institutions involved. Hence, although not all the information can be fully verified, the prestige of the authors and their continuous interactions with the community and the different institutions makes the TOP 500 the most trusted source of HPC information.
One can sign up in their webpage, download data and receive periodic information and newsletters.
What is an exa-scale system and how does the Frontier system look like?
An exa-scale supercomputer is a supercomputer that has the power to compute more than 1 exa-Flop operations per second, that is, more than 1018 floating point operations per second (EFLOPS or EFlop/s). An EFLOP is equivalent to 1,000,000 Tera-Flops (TFLOPS or TFlop/s, used in the rest of the text, being 1 TFLOP equivalent to 1012 floating point operations per second).
The numbers are astonishing.
Frontier is a system that contains 8.73 million Central Processing Units (CPU) cores and 8.14 million Graphics Processing Units (GPU) cores. Its peak performance is 1,685,651 TFLOPS, which means that it can reach 1,685,651,000,000,000,000 floating point operations per second, theoretically. One gets lost with such many zeros and these humongous magnitudes.
Compare this to the number 1 system in the first TOP500 list that appeared back in June 1993: it was a CM-5 supercomputer built by Thinking Machines Corporation with 1,024 cores and a measured performance (not peak) of 59.7 GFLOPS (59,700,000,000 floating point operations per second). This is 18.5M less performance – yes, eighteen million – than the measured performance of Frontier, which is 1,102,000 TFLOPS.
The estimated cost to build Frontier is $600M and the system consumes 21MWatts of power and it occupies a room of 680 square meters.
Aurora will probably be the 2nd exa-scale machine to be constructed and it is expected to be built towards the end of 2022 at the Argonne National Laboratory, Illinois, United States. It will use using Intel processors for CPUs and GPUs as well.
Stay tuned for the TOP500 list update in Q4 2022 and Q2 2023. It will be interesting to see the evolution of the exa-scale HPC race.
Current top 10 HPC systems and locations
The following table shows the top 10 HPC systems from the TOP500 list and it is a summary of the information available in the TOP500 website. Although these systems are more than just CPUs and GPUs, the table below focuses specially on these factors.
| Position | Name | Location | Built in or last update in | Achieved performance Rmax (TFLOPS) | Peak performance Rpeak (TFLOPS) | Manufacturer | Main CPU provider | Number of CPU cores | Main GPU provider | Number of GPU cores | Operating System |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Frontier | United States | 2021 | 1,102,000 | 1,685,651 | HPE | AMD (x86 ISA) | 8,730,112 | AMD | 8,138,240 | HPE Cray OS (Linux) |
| 2 | Supercomputer Fugaku | Japan | 2020 | 442,010 | 537,212 | Fujitsu | Fujistsu (ARM ISA) | 7,630,848 | None | - | Red Hat Enterprise Linux |
| 3 | LUMI | Finland | 2022 | 151,900 | 214,352 | HPE | AMD (x86 ISA) | 1,110,144 | AMD | 1,034,880 | HPE Cray OS (Linux) |
| 4 | Summit | United States | 2018 | 148,600 | 200,795 | IBM | IBM (Power ISA) | 2,414,592 | NVIDIA | 2,211,840 | RHEL 7.4 (Linux) |
| 5 | Sierra | United States | 2018 | 94,640 | 125,712 | IBM / NVIDIA / Mellanox | IBM (Power ISA) | 1,572,480 | NVIDIA | 1,382,400 | Red Hat Enterprise Linux |
| 6 | Sunway TaihuLight | China | 2016 | 93,015 | 125,436 | NRCPC | (ShenWei ISA) | 10,649,600 | None | - | Sunway RaiseOS 2.0.5 (Linux) |
| 7 | Perlmutter | United States | 2021 | 70,870 | 93,750 | HPE | AMD (x86 ISA) | 761,856 | NVIDIA | 663,552 | HPE Cray OS (Linux) |
| 8 | Selene | United States | 2020 | 63,460 | 79,215 | NVIDIA | AMD (x86 ISA) | 555,520 | NVIDIA | 483,840 | Ubuntu 20.04.1 LTS (Linux) |
| 9 | Tianhe-2A | China | 2018 | 61,445 | 100,679 | NUDT | Intel (x86 ISA) | 4,981,760 | Matrix-2000 | 4,554,752 | Kylin Linux |
| 10 | Adastra | France | 2022 | 46,100 | 61,608 | HPE | AMD (x86 ISA) | 319,072 | AMD | 297,440 | HPE Cray OS (Linux) |
Some interesting information and facts from this table.
Achieved performance and peak performance are based on the Rmax and Rpeak scores respectively. Rmax refers to the real measured performance of the system when running the LINPACK benchmark, which consists of a linear system of equations of order ‘n’ that are solved using LU decomposition with partial row pivoting. Peak performance, on the other hand, is the theoretical maximum performance and is it mainly computed by adding the individual peak performances of all individual computing nodes (CPUs, GPUs and other accelerators). Note that observed performance is always lower than peak performance.
There is variety in the Instruction Set Architecture (ISA), which is the repertoire and format of low-level instructions executed by the CPU: x86, Power, ARM… There is also variety in the GPU architecture (GPUs from NVIDIA, AMD and probably Intel once the Aurora system is in place) and manufacturers (HPE, Fujitsu, IBM, …). There is no variety with respect of the underlying operating system: all of them depend on one or another flavor of Linux.
Although most systems are built for public or academic research, there is a notable exception in the TOP 10. Selene, in position number 8, is build by NVIDIA and it is a system entirely owned by a private company. There are other exceptions from Microsoft, Samsung and Saudi Aramco, but these privately owned systems fall in positions between 10 and 20 in the list (one can download the raw list with all the parameters from the TOP500 website).
Another contrasting system is Sunway TaihuLight in position 6 from China. This is a system that uses its own ISA (ShenWei) and there are few internal details about it. The system does not use any other type of processing unit other than the CPUs (no GPUs or other accelerators) and the running frequency of its processors is 1.4 GHz (the rest of the systems run at frequencies between 2GHz and 3 GHz). China is building its own microarchitecture to remove any dependency on western countries and western technology whatsoever. Sunway TaihuLight was the response of the Chinese government to the prohibition by the US to upgrade the Tianhe-2A system (now in position number 9) using Intel’s technology back in 2015.
What is the position of Europe in the TOP500?
Downloading the TOP500 list in Excel format is very interesting to dig a bit more on the available data.
The following tables and figures show the distribution of HPC systems and capacity geographically (North America includes the United States and Canada) and divided in segments. The TOP500 list categorizes the systems in different segments: research, academia, government, industry, vendor and others. I have assumed that the first 3 (research, academia and government) are public initiatives and I have split the data into public and all segments.
| Area | Number of systems - public | Total peak performance (TFLOPS) - public | Peak performance / system (TFLOPS) - public | Number of systems - ALL | Total peak performance (TFLOPS) - ALL | Peak performance / system (TFLOPS) - ALL |
|---|---|---|---|---|---|---|
| Europe | 85 | 972,345.97 | 11,439.36 | 118 | 1,294,550.94 | 10,970.77 |
| North America | 81 | 2,785,615.97 | 34,390.32 | 142 | 3,230,788.20 | 22,752.03 |
| Asia | 63 | 1,228,454.62 | 19,499.28 | 228 | 2,251,574.02 | 9,875.32 |
| Rest | 6 | 32,924.54 | 5,487.42 | 12 | 71,528.50 | 5,960.71 |
Europe accumulates 36% of all the public HPC systems in the TOP500 list, but this percentage drops to 24% when all the segments are considered. On the other hand, it is interesting to see that Asia has more private HPC systems in the list (165, which is the result of 228 – 63) than public ones (63). From a country perspective, China owns 173 HPC systems from the TOP500 list, followed by the United States with 128.
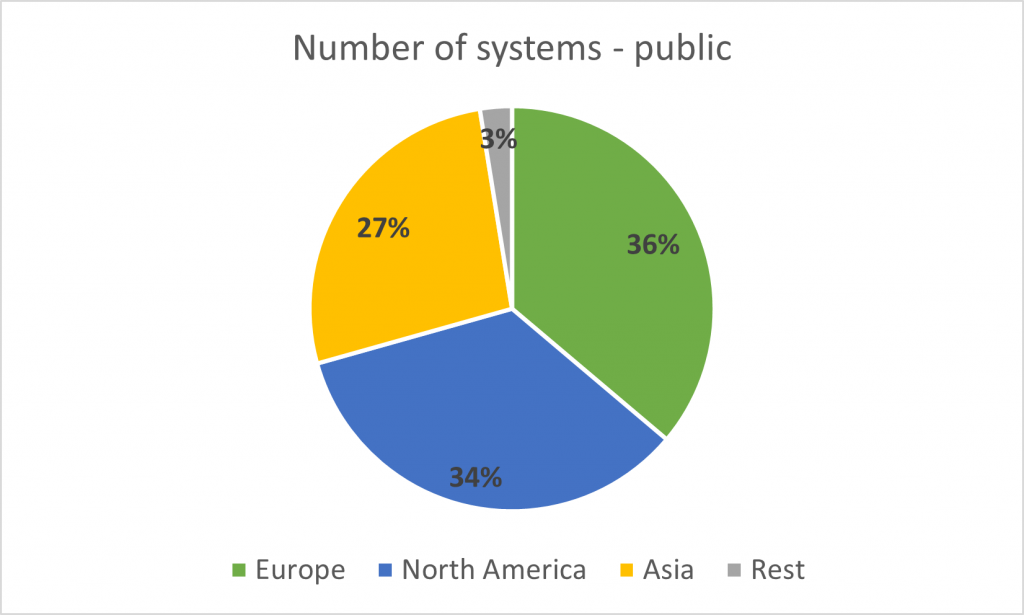
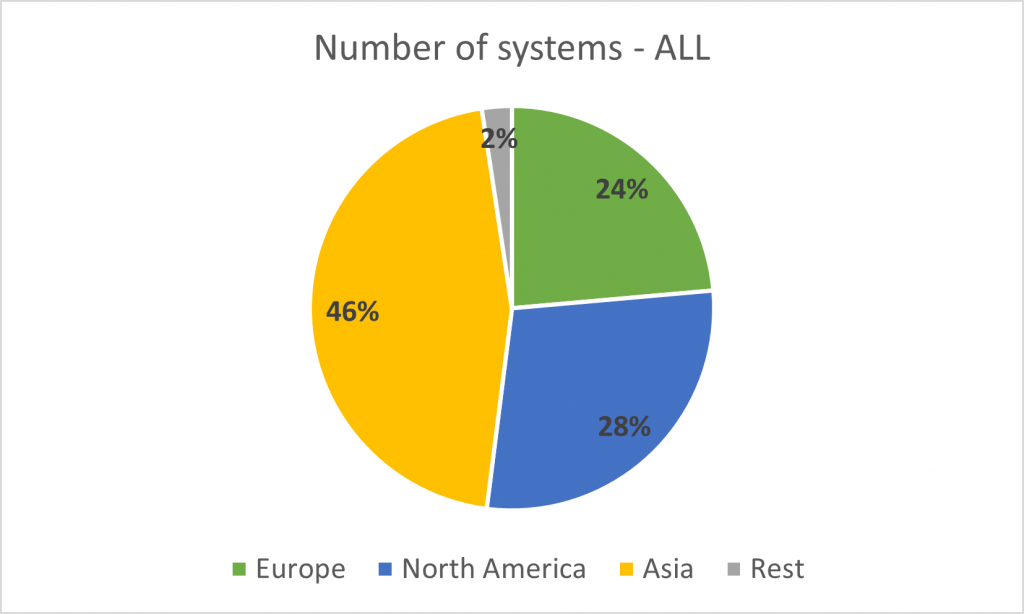
Although Europe has a good presence in terms of number of HPC systems, we can see that their size is smaller than in other geographies by looking at their capacity (in this case, peak performance). As said Europe has 36% of all public HPC systems and 24% of all HPC systems, but they accumulate 19.4% and 19% of the worldwide peak performance. This can also be seen by the average peak performance per system. The peak performance of public and all HPC systems in Europe is 11,439 and 10,970 TFLOPS respectively. Note that there is not much difference between public and all systems in Europe, while there are bigger differences between these two groups in America (34,390 TFLOPS per public system on average vs. 22,752 TFLOPS for all segments) and Asia (19,499 vs. 9,875 TFLOPS).
Europe created the European High Performance Computing Joint Undertaking (EuroHPC JU), a pan-European effort to compete in the HPC race with the United States, Japan and China. Among other programs and activities, EuroHPC JU has built a roadmap to deploy new HPC systems. The following table summarizes them.
| Name | Location | Status | Peak performance (TFLOPS) | Comments |
|---|---|---|---|---|
| LUMI | Finland | Operating since 2022 | 550,000 | Position 3 in TOP 500 June'22 |
| Vega | Slovenia | Operating since 2021 | 10,050 | Position 131 (CPU partition) and 172 (GPU partition) in TOP 500 June'22 |
| MeluXina | Luxembourg | Operating since 2021 | 18,290 | Position 306 (CPU partition) and 48 (GPU partition) in TOP 500 June'22 |
| Discoverer | Bulgaria | Operating since 2021 | 5,940 | Position 113 in TOP 500 June'22 |
| Karolina | Czech Republic | Operating since 2021 | 12,910 | Position 202 (CPU partition) and 79 (GPU partition) in TOP 500 June'22 |
| Leonardo | Italy | Operational in Q3 2022 (expected) | 323,400 | |
| Deucalion | Portugal | Under construction | 10,000 | |
| Mare Nostrum 5 | Spain | Under construction | 314,000 | It will substitute Mare Nostrum 4 and prior systems |
| TBD | Germany | Under definition | TBD | |
| TBD | Greece | Under definition | TBD | |
| TBD | Hungary | Under definition | TBD | |
| TBD | Ireland | Under definition | TBD | |
| TBD | Poland | Under definition | TBD |
Some of them are already available, while others are under construction or under definition. All of them are pre exa-scale systems since none has the capacity to execute 1 EFLOPS (1,000,000 TFLOPS) yet. It seems, though, that “Jupiter”, the system to be installed in Germany, will be Europe’s first exa-scale system.
The peak performance of each system differs between the one reported at the EuroHPC JU website and the one reported in the TOP500 list, although I would not bother much about it: the difference is probably due to the fact that the TOP500 uses the Rpeak metric, whereas it is not clear what the EuroHPC JU website is using.
The only caveat of reporting different metrics / data is that one cannot do an apples-to-apples comparison, so we do not know where these systems would stand in the TOP500 list if they were operational today. We only know the position of the systems that are available today, LUMI occupying the third place in the June 2022 list.
Mare Nostrum 5 in Barcelona is the system that deeper touches my heart. I worked many years at the facility that Intel Labs had near the Barcelona Supercomputing Center and I had and I still have many interactions with researchers in that organization.
Although there are not many details about the exact configuration of Mare Nostrum 5, it seems it will have several parts, each with a specific CPU / GPU configuration targeting specific application domains. Mare Nostrum will probably be a hybrid system including CPUs from Intel, AMD and NVIDIA (in this case, using the ARM instruction set architecture), and GPUs from NVIDIA, AMD and Intel. There were debates about adding some sort of “European” hardware, but the European Processor Initiative (EPI) based on RISC-V is not ready yet. The deployment of Mare Nostrum 5 has been delayed several times (it is common in all this sort of infrastructures) and it does not have, to the best of my knowledge, a public kick-off date.
Summary
The TOP500 HPC list is the best source to see the evolution of the HPC race and how each continent and country is positioned in this area. The United States is ahead in terms of accumulated HPC performance (2.7 times more than China, in 2nd position), the first exa-scale computer named Frontier and the second one in the horizon (expected in Q4 2022). In terms of number of HPC systems, China is ahead with 173 systems in the TOP500, followed by 128 from the United States.
Europe is trying to compete through the EuroHPC JU initiative, among other smaller efforts, and it expects to have its first exa-scale system set up in Germany (without any specific public due date yet). The average size of HPC systems in Europe is smaller than other geographies, which may be explained by a lesser unified market with more pressure from individual governments. The North American market (clearly dominated by the United States) and the Asian market (dominated by China and Japan) are more unified in this regard.
From a business perspective, it is a stimulating time since there is a fierce competition among different CPU vendors, GPU vendors and manufacturers. And this is just the tip of the iceberg, since an HPC system is not only compute power, but cooling methods and systems, memory, permanent storage, connectivity and networking, … And software! The best HPC system not equipped with a proper operating system, programming languages and compilers, libraries and tools is useless. But let’s leave the discussion here for today.
Let’s stay tuned with future TOP500 releases.
References
- https://www.top500.org/
- https://www.top500.org/news/ornls-frontier-first-to-break-the-exaflop-ceiling/
- https://eurohpc-ju.europa.eu/index_en
- https://eurohpc-ju.europa.eu/about/our-supercomputers_en
- https://eurohpc-ju.europa.eu/marenostrum5-new-eurohpc-world-class-supercomputer-spain-2022-06-16_en
- https://www.bsc.es/
- https://www.nextplatform.com/2022/06/16/atos-wins-marenostrum-5-deal-at-barcelona-supercomputing-center/
- https://en.wikipedia.org/wiki/Frontier_(supercomputer)